zUMIs: A fast and flexible pipeline to process RNA sequencing data with UMIs
by S. Parekh, C. Ziegenhain, B. Vieth, W. Enard and I. Hellmann
26.05.2018
Background
Single cell RNA-seq (scRNA-seq) experiments typically analyze hundreds or thousands of cells after amplification of the cDNA. The high throughput is made possible by the early introduction of sample-specific barcodes (BCs) and the amplification bias is alleviated by unique molecular identifiers (UMIs). Thus the ideal analysis pipeline for scRNA-seq data needs to efficiently tabulate reads according to both BC and UMI.
Findings
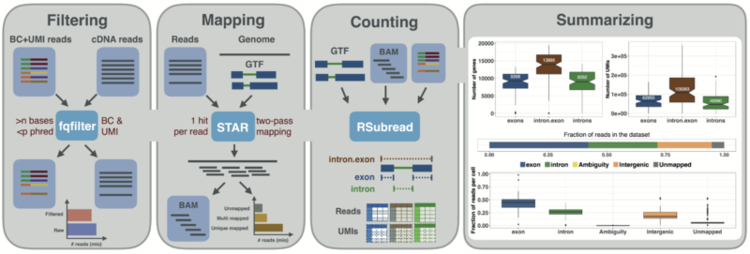
zUMIs is a pipeline that can handle both known and random BCs and also efficiently collapses UMIs, either just for Exon mapping reads or for both Exon and Intron mapping reads. If BC annotation is missing, zUMIs can accurately detect intact cells from the distribution of sequencing reads. Another unique feature of zUMIs is the adaptive downsampling function, that facilitates dealing with hugely varying library sizes, but also allows to evaluate whether the library has been sequenced to saturation. To illustrate the utility of zUMIs, we analysed a single-nucleus RNA-seq dataset and show that more than 35% of all reads map to Introns. We furthermore show that these intronic reads are informative about expression levels, significantly increasing the number of detected genes and improving the cluster resolution.
Conclusions
zUMIs flexibility allows to accommodate data generated with any of the major scRNA-seq protocols that use BCs and UMIs and is the most feature-rich, fast and user-friendly pipeline to process such scRNA-seq data.
Avaliability
zUMIs is open source and available at github!
The manuscript is published in GigaScience!